Les indicateurs maintenance qui mentent : MTBF, MTTR, disponibilité
Les indicateurs maintenance qui mentent : MTBF, MTTR, disponibilité
Introduction
Votre tableau de bord affiche MTBF = 480 h sur la presse n°3. Vendredi 14h, votre chef de prod vous appelle pour le troisième arrêt de la semaine. Quelqu'un ment, et ce n'est pas votre équipe.
Les trois KPI canoniques de la maintenance industrielle, MTBF, MTTR et disponibilité, sont mathématiquement justes. Tous les CMMS du marché savent les calculer en quelques secondes. Le problème n'est pas la formule.
Le problème, c'est que ces formules s'appliquent sur des données non nettoyées, et qu'elles produisent alors des nombres opérationnellement faux. Des nombres qui finissent en revue mensuelle, en CAPEX déféré, en cibles budgétaires inatteignables. Bref, en décisions stratégiques bâties sur du sable.
Cet article diagnostique trois failure modes classiques des KPI maintenance, avec chiffres terrain à l'appui, et fournit pour chacun une correction concrète, implémentable sans changer de logiciel.
Pour qui : responsables maintenance, ingénieurs fiabilité, chefs de prod, directions techniques. Pas utile si vous n'avez pas encore de CMMS, ou si vos arrêts non planifiés sont rares (moins d'un par mois).
MTBF gonflé : préventif et correctif mélangés
Le mensonge le plus répandu, et le plus invisible.
🟦 À RETENIR — sélectionne ce paragraphe + clique "À retenir" dans la toolbar :
MTBF (Mean Time Between Failures, NF EN 13306, ISO 14224 §6.5) = uptime cumulé divisé par le nombre de défaillances. Mesure de référence de la fiabilité d'un équipement réparable.
Le piège
La plupart des CMMS calculent le MTBF sur tous les WO terminés : préventifs, correctifs, inspections, tout ce qui ferme dans la même bucket. Résultat : plus vous faites de maintenance préventive (donc plus vous êtes mature), plus votre MTBF affiché grimpe, sans que vos équipements soient plus fiables.
Le bruit du préventif amortit le signal du correctif. Et le signal du correctif, c'est exactement ce qu'on cherche à mesurer.
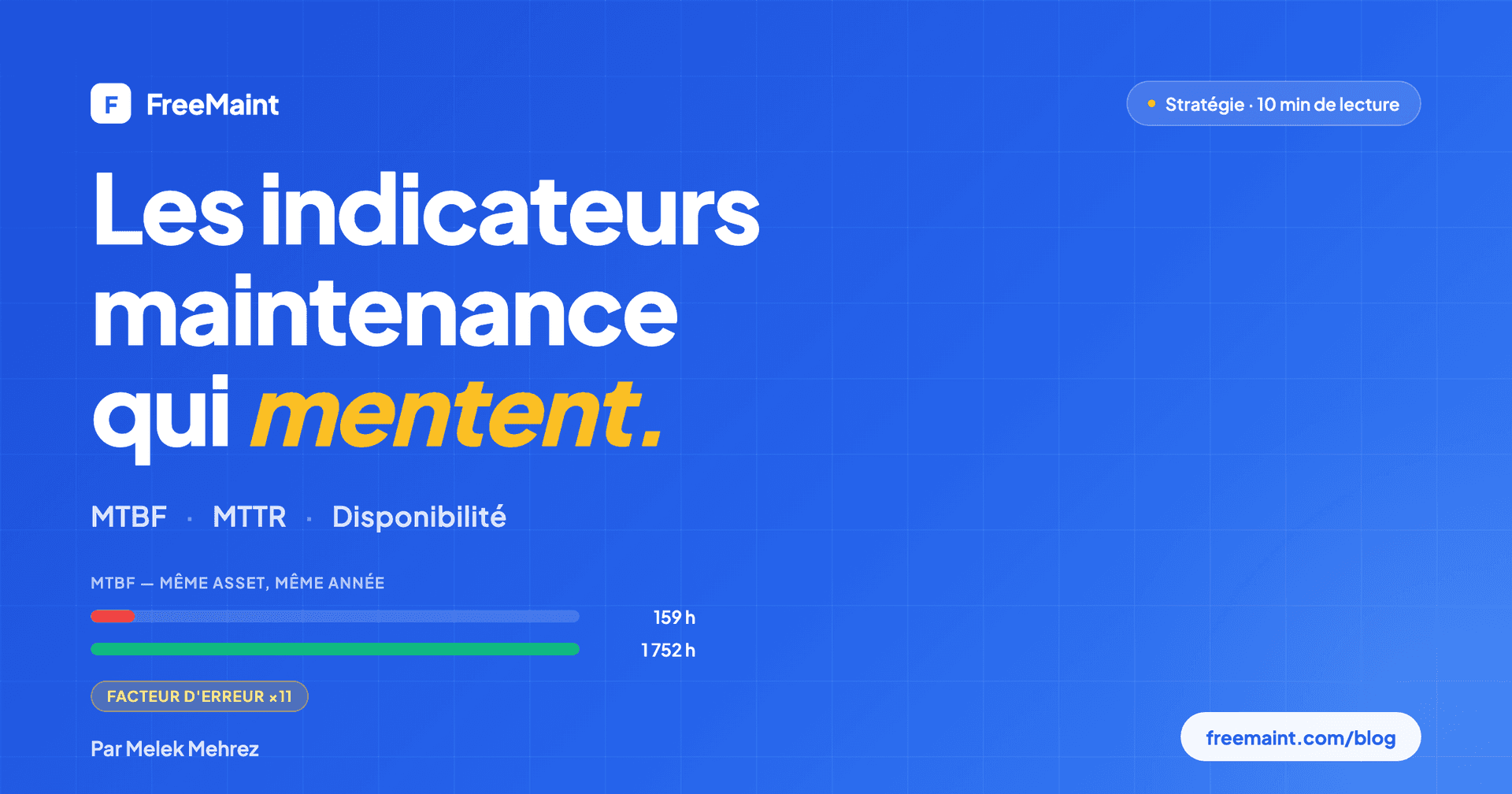
Exemple chiffré : asset X sur 12 mois (8 760 h calendaires)
50 WO préventifs réalisés (graissage, contrôles) + 5 pannes correctives.
Méthode de calcul | Formule | Résultat | Lecture opérationnelle |
|---|---|---|---|
MTBF naïf (tous WO) | 8 760 / 55 | 159 h | "Asset stable" |
MTBF correct (correctifs only) | 8 760 / 5 | 1 752 h | Tombe en panne tous les 2 mois |
Facteur d'erreur : ×11.
🟠 ATTENTION — sélectionne ce paragraphe + clique "Attention" dans la toolbar :
Un asset qui panne tous les 2 mois est étiqueté "fiable" en revue mensuelle. Le CAPEX de remplacement reste reporté année après année. Le jour où l'asset lâche en plein cycle critique, la direction découvre le mensonge. Trop tard.
Comment recalculer
Étape | Action | Détail |
|---|---|---|
1 | Séparer les types de WO au niveau data | Préventif, correctif, amélioration, inspection, urgence. Taxonomie ISO 14224 §B.2 utilisable telle quelle. |
2 | Filtrer le calcul |
|
3 | Distinguer défaillance fonctionnelle et potentielle | Un préventif qui détecte une dégradation avant la panne n'est pas une panne. Le compter comme défaillance tue l'intérêt même de l'inspection. |
🟢 CONSEIL PRATIQUE — sélectionne ce paragraphe + clique "Conseil pratique" dans la toolbar :
Sur votre prochaine revue mensuelle : recalculez le MTBF sur correctifs uniquement sur un seul asset critique. Comparez avec le MTBF affiché. Le facteur d'erreur va parler de lui-même, et le débat sur la taxonomie démarrera tout seul.
MTTR sous-estimé : le blast radius des arrêts en cascade
Quand le coût réel d'une panne est invisible dans le KPI.
🟦 À RETENIR — sélectionne ce paragraphe + clique "À retenir" :
MTTR (Mean Time To Repair) = temps moyen entre l'ouverture du WO et sa complétion. Souvent confondu avec active repair time (le temps réellement passé à réparer).
Le piège
Le MTTR mesure la réparation de l'équipement défaillant. Mais une panne crée presque toujours un blast radius : la machine X tombe, la ligne Y arrêtée en aval, la matière Z dégradée en attendant, l'équipe immobilisée. Le MTTR sur le WO de X ne capture rien de cela.
Exemple chiffré : capteur HS sur presse n°3, vendredi 8h
Étape | Élément impacté | Durée | Coût direct |
|---|---|---|---|
1 | Machine X : remplacement capteur | 2 h | 50 € pièce + 2 h tech = 200 € |
2 | Ligne Y aval : attente diagnostic + commande | +4 h | 6 opérateurs immobilisés ≈ 1 800 € |
3 | Matière Z dans la presse : résine figée, rework | +1 jour-équipe | Matière + nettoyage ≈ 4 500 € |
4 | Pénalité contractuelle client | livraison retardée | 3 000 € |
Total | Downtime opérationnel réel | ~32 h | ~9 500 € |
MTTR affiché : 2 h. Downtime opérationnel réel : 32 h. Facteur d'erreur : ×16.
🟠 ATTENTION — sélectionne ce paragraphe + clique "Attention" :
Le coût horaire de panne calculé sur le MTTR (200 €) est ridiculement sous-évalué. Pas de business case pour investir dans la fiabilité parce que "ça coûte rien". Le vrai coût (perte de production + matière + équipe = 9 500 €) reste invisible. Le management refuse les budgets fiabilité parce que les KPI ne justifient pas la dépense.
Comment recalculer
Étape | Action | Détail |
|---|---|---|
1 | Modéliser le blast radius | Créer un objet "Shutdown" ou "Incident parent" qui regroupe les WO enfants déclenchés par la cascade. La plupart des CMMS modernes le permettent via un champ |
2 | Calculer le MTTR sur le parent |
|
3 | Distinguer active repair time et downtime | ISO 14224 §3.13 fait cette distinction depuis 30 ans. Vos rapports doivent les afficher côte à côte. Pas le même nombre. |
Disponibilité gonflée : les micro-arrêts non comptés
1 point d'OEE perdu dans le brouillard statistique.
🟦 À RETENIR — sélectionne + clique "À retenir" :
Availability = Uptime / (Uptime + Downtime). Au cœur du calcul OEE (Overall Equipment Effectiveness) = Availability × Performance × Quality.
Le piège
La disponibilité ne compte que les downtimes loggés via un WO. Mais sur une ligne de production typique, environ 60 % des arrêts sont des micro-arrêts de moins de 15 minutes : calage, réglage, purge, micro-bourrage, attente matière, changement de format mineur.
Ces arrêts ne génèrent pas de WO parce que l'opérateur les résout en 5 minutes sans rien dire à personne. Résultat : invisibles dans le CMMS, invisibles dans la dispo, invisibles dans l'OEE.
Exemple chiffré : ligne 24/7 sur 1 mois (720 h théoriques)
Indicateur | Uptime | Downtime loggé (WO) | Micro-arrêts (50 × 10 min) | Calcul | Résultat |
|---|---|---|---|---|---|
Dispo apparente (CMMS seul) | 712 h | 8 h | invisibles | 712 / 720 | 98,9 % |
Dispo réelle (avec micro-arrêts) | 703,7 h | 8 h | 8,3 h | 703,7 / 720 | 97,8 % |
Écart : 1 point. Semble cosmétique. Pas sur l'OEE.
Composant OEE | Performance | Qualité | Calcul | OEE |
|---|---|---|---|---|
OEE nominal (dispo apparente) | 92 % | 98 % | 98,9% × 92% × 98% | 89,2 % |
OEE réel (dispo avec micro-arrêts) | 92 % | 98 % | 97,8% × 92% × 98% | 88,2 % |
🟠 ATTENTION — sélectionne + clique "Attention" :
Sur une usine à 50 M€ de CA, 1 point d'OEE perdu représente environ 500 k€ de marge évaporée chaque année dans le brouillard statistique. La cible OEE budgétée devient inatteignable parce que la baseline est fausse. Les équipes sont jugées sur un mensonge.
Comment recalculer
Étape | Action | Détail |
|---|---|---|
1 | Instrumenter les micro-arrêts | Compteur |
2 | Aggréger en time-buckets | Pas un WO par micro-arrêt (overhead administratif insoutenable). Buckets horaires ou journaliers via meter readings dans le CMMS. Une ligne par jour suffit. |
3 | Distinguer 3 catégories | Breakdown (>1 h, ouvre WO), short stop (15-60 min, loggé sans WO), minor stoppage (<15 min, compteur agrégé). Chacune reportée séparément. |
🟢 CONSEIL PRATIQUE — sélectionne + clique "Conseil pratique" :
La norme SEMI E10-0814 (semi-conducteur) distingue 6 états d'équipement. C'est le standard le plus rigoureux au monde sur ce sujet. À adapter selon le niveau de maturité de votre site, sans copier-coller à l'identique.
Tableau récapitulatif
À imprimer et à apporter à votre prochain comité.
Indicateur | Faille classique | Calcul correct | Impact direction |
|---|---|---|---|
MTBF | Mélange PM + correctif dans le compteur de défaillances | Filtrer | Risque caché ×5 à ×10 |
MTTR | WO start → complete only, ignore le blast radius | Modéliser un shutdown parent + downtime cascadé | Coût horaire panne ×3 à ×15 |
Disponibilité | Micro-arrêts <15 min jamais loggés | Instrumenter via SCADA + agréger en meter readings | OEE faux de 1 à 3 points |
Mise en pratique : 3 actions pour votre prochaine revue mensuelle
Aucune de ces actions ne demande un nouveau logiciel ou un budget. Juste une taxonomie de WO propre, un objet "shutdown parent" dans votre CMMS existant, et un cron qui agrège les micro-arrêts depuis votre SCADA.
Étape 1 : recalculer le MTBF sur correctifs uniquement. Sur un asset critique, recalculez le MTBF en excluant les WO préventifs. Comparez avec le MTBF affiché. Le facteur d'erreur va parler de lui-même.
Étape 2 : logger le prochain incident avec un incident_id. Sur le prochain arrêt non routine, loggez non seulement le WO de réparation mais aussi un identifiant d'incident qui groupe tous les WO impactés. Calculez le downtime réel sur ce parent.
Étape 3 : demander au SCADA vos micro-arrêts du mois. Demandez à votre équipe automatisme le nombre de micro-arrêts <15 min sur le mois passé. Comparez à zéro, ce que votre CMMS croit. Vous allez avoir une surprise.
Questions fréquentes
Q : Pourquoi mon MTBF est-il trompeur ?
R : Le MTBF calculé sur tous les ordres de travail terminés mélange préventifs et correctifs. Plus vous avez de PM réalisés, plus le MTBF affiché monte, sans que votre équipement soit plus fiable. La correction : filtrer le calcul sur les seuls WO de type CORRECTIVE ou EMERGENCY, conformément à la taxonomie ISO 14224.
Q : Qu'est-ce que le blast radius d'une panne ?
R : Le blast radius désigne l'ensemble des conséquences en cascade d'une panne : machine X tombe, ligne Y attend, matière Z se gâte, équipe en attente. Le MTTR calculé sur le seul WO de réparation de X ne capture rien de tout cela. Pour mesurer le coût réel, il faut modéliser un objet shutdown parent qui regroupe tous les WO impactés et calculer le MTTR sur ce parent.
Q : Pourquoi ma disponibilité affichée est-elle fausse ?
R : La disponibilité ne compte que les downtimes loggés dans le CMMS via un ordre de travail. Mais environ 60 % des arrêts industriels sont des micro-arrêts de moins de 15 minutes (calage, réglage, purge, micro-bourrage) que l'opérateur résout en 5 minutes sans créer de WO. Ces minutes invisibles font gonfler artificiellement le taux de disponibilité affiché de 1 à 3 points sur l'OEE.
Q : Comment corriger mes KPI sans changer de logiciel ?
R : Aucun des 3 fixes ne demande un nouveau logiciel. (1) Ajouter un champ maintenance_type sur vos WO pour distinguer préventif, correctif, urgence. (2) Introduire un champ incident_id pour grouper les WO d'un même blast radius. (3) Instrumenter les micro-arrêts via votre SCADA et agréger via meter readings. Le tout dans votre CMMS existant.
Conclusion
Ces 3 indicateurs ne sont pas mauvais. C'est leur configuration qui ment.
Les 3 points à retenir :
Le MTBF n'a de sens que filtré sur les défaillances réelles. Tout ce qui ferme un WO n'est pas une panne.
Le MTTR seul cache le vrai coût d'une panne. Le blast radius doit être modélisé pour mesurer le downtime opérationnel.
La disponibilité est fausse tant que les micro-arrêts ne sont pas instrumentés. SCADA + meter readings est la voie pragmatique.
Prochaine étape concrète : sur votre prochaine revue mensuelle, recalculez le MTBF sur correctifs uniquement sur un seul asset critique. L'écart va lancer la conversation.
Références
ISO 14224:2016 — Industries du pétrole, du gaz naturel et pétrochimique : collecte et échange de données de fiabilité et de maintenance pour les équipements
NF EN 13306 — Terminologie de la maintenance
SEMI E10-0814 — Specification for Definition and Measurement of Equipment Reliability, Availability, and Maintainability (RAM)
Seiichi Nakajima (1988) — TPM: An Introduction, référence historique sur la décomposition OEE et les "six big losses"
Article publié initialement sur freemaint.com/blog le 26 mai 2026.
Melek Mehrez est fondateur de FreeMaint, CMMS freemium dont la taxonomie de WO est nativement alignée sur ISO 14224.
Commentaires
Chargement des commentaires…